This is the first part of a full pipeline [Exploratory data analysis, data cleaning and preprocessing, modeling, error analysis]
As I mentioned before, Madrid is a beautiful city and has been a popular destination among expats for years. This is an attempt to build a model that would predict rental price of apartments in Madrid based on the factors like area, location, number of rooms, number of bathrooms, etc.
Full project with data is available on github
#Importing libraries
import math
import pandas as pd
import numpy as np
import seaborn as sns
from collections import Counter
import mpld3
mpld3.enable_notebook()
import matplotlib.pyplot as plt
import plotly.express as px
import plotly.graph_objects as go
import plotly.io as pio
import os
from jupyterthemes import jtplot
jtplot.style(theme='monokai', context='notebook', ticks=True, grid=False)
%config IPCompleter.greedy=True#Importing data
df = pd.read_csv('rental_price_june.csv', header ='infer') #Deleting duplicates if any
df.drop_duplicates(keep='first')
df.reset_index(drop=True, inplace=True)This is a pretty big dataframe with 17,094 rows and 55 columns. The target value is rent_price
df.info()
I will delete the columns below, because 90% is NAs and the rest is irrelevant to the target value at this stage.
df = df.drop(axis =1, columns = ['description', 'sq_mt_useful', 'sq_mt_allotment','latitude','longitude', 'is_exact_address_hidden', 'street_name', 'portal', 'door', 'operation', 'rent_price_by_area', 'is_rent_price_known', 'buy_price', 'buy_price_by_area', 'is_buy_price_known', 'are_pets_allowed', 'has_private_parking', 'has_public_parking',
'has_parking', 'is_parking_included_in_price', 'parking_price', 'is_orientation_north', 'is_orientation_west', 'is_orientation_east','agency_id'])I will split L40 and L30 columns and create District and Neighborhood columns:
df['District'] = df.l30_area_id.str.split(r'[:()€]', expand=True) [1]
df['Neighborhood'] = df.l40_area_id.str.split(r'[:()€]', expand=True) [1]I will use groupby function and find mean price for each. It will help me understand average price in a specific area.
mean_price_Distr = df.groupby("District")['rent_price'].mean().sort_values(ascending=True).reset_index()
mean_price_Neigh = df.groupby("Neighborhood")['rent_price'].mean().sort_values(ascending=True).reset_index()I will create series based on mean_price and use this dictionary in a function below
mean_price_dict_Distr = pd.Series(mean_price_Distr.rent_price.values,index=mean_price_Distr.District).to_dict()
mean_price_dict_Neigh = pd.Series(mean_price_Neigh.rent_price.values,index=mean_price_Neigh.Neighborhood).to_dict()Simple functions. Returns mean price in given area
def mean_price_distr(District):
if District in mean_price_dict_Distr.keys():
return round(mean_price_dict_Distr[District])
def mean_price_neigh(Neighborhood):
if Neighborhood in mean_price_dict_Neigh.keys():
return round(mean_price_dict_Neigh[Neighborhood])I create new columns Avg_price_distr & Avg_price_neigh
df['Avg_price_distr'] = df.District.apply(mean_price_distr)
df['Avg_price_neigh'] = df.Neighborhood.apply(mean_price_neigh)Distribution of target variable
if not os.path.exists("images"):
os.mkdir("images")
fig = px.histogram(df, x="rent_price", barmode='group')
fig.update_layout(
autosize=False,
width=1200,
height=800,
title={
'text': "Distribution of rent price",
'y':0.9,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'},
bargap=0.2,
bargroupgap=0.1
)
fig.show()
pio.write_image(fig,"images/Distribution_rent_price1.png")
I will drop outliers from the dataframe and plot it again
df = df[df['rent_price']<5000]
fig = px.histogram(df, x="rent_price", barmode='group', nbins=30)fig.update_layout(
autosize=False,
width=1200,
height=800,
title={
'text': "Distribution by rent price",
'y':0.9,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'},
bargap=0.2,
bargroupgap=0.1
)
fig.show()
pio.write_image(fig,"images/Distribution_rent_price2.png")
Distribution of sq_mt_built
fig = px.histogram(df, x="sq_mt_built", barmode='group', nbins =20)
fig.update_layout(
autosize=False,
width=1200,
height=800,
title={
'text': "Distribution of flats/houses by size",
'y':0.9,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'},
bargap=0.2,
bargroupgap=0.1
)
fig.show()
pio.write_image(fig,"images/sq_mt_built1.png")
I am interested in apartments/houses where sq_mt_built is less than 300. I will drop outliers here, too.
df = df[df['sq_mt_built']<300]
fig = px.histogram(df, x="sq_mt_built", barmode='group', nbins =15)fig.update_layout(
autosize=False,
width=1200,
height=800,
title={
'text': "Distribution of flats/houses by size",
'y':0.9,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'},
bargap=0.2,
bargroupgap=0.1
)
fig.show()
pio.write_image(fig,"images/sq_mt_built2.png")
Houses with more than 5 rooms will definitely affect our model negatively. I will drop these listings.
df = df[df['n_rooms']<6]
fig = px.histogram(df, x="n_rooms", barmode='group')fig.update_layout(
autosize=False,
width=1200,
height=700,
title={
'text': "Distribution of flats/houses by # of rooms",
'y':0.9,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'},
bargap=0.2,
bargroupgap=0.1
)
fig.show()
pio.write_image(fig,"images/n_rooms.png")
I will drop listings where n_bathrooms is more than 4
fig = px.histogram(df, x="n_bathrooms", barmode='group')
fig.update_layout(
autosize=False,
width=1200,
height=700,
title={
'text': "Distribution of flats/houses by # of bathrooms",
'y':0.9,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'},
bargap=0.2,
bargroupgap=0.1
)
fig.show()
pio.write_image(fig,"images/n_bathrooms.png")
Number of houses/flats for rent by districts
p = df.groupby('District')['l30_area_id'].count().sort_values(ascending=False).reset_index()
p = p.rename(columns={'l30_area_id': 'Houses_for_rent'})
fig = px.bar(p, x='District', y='Houses_for_rent')
fig.update_layout(
autosize=False,
width=1200,
height=700,
title={
'text': "Number of houses/flats for rent by districts",
'y':0.9,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'})
fig.show()
pio.write_image(fig,"images/flats_for_rent_districts.png")
Number of houses/flats for rent by neighborhoods
p = df.groupby('Neighborhood')['l40_area_id'].count().sort_values(ascending=False).reset_index()
p = p.rename(columns={'l40_area_id': 'Houses_for_rent'})
fig = px.bar(p, x='Neighborhood', y='Houses_for_rent')
fig.update_layout(
autosize=False,
width=1200,
height=700,
title={
'text': "Number of houses/flats for rent by neighborhoods",
'y':0.9,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'})
fig.show()
pio.write_image(fig,"images/flats_for_rent_neighborhoods.png")
Mean rent price by districts + mean rent price in Madrid (red line)
p = df.groupby('District')['Avg_price_neigh'].mean().sort_values(ascending=False).reset_index()
mean = df.rent_price.mean()
fig = px.bar(p, x='District', y='Avg_price_neigh')
fig.update_layout(
autosize=False,
width=1200,
height=700,
title={
'text': "Average rent prices by districts",
'y':0.9,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'})
fig.update_layout(
shapes=[
dict(type="line", xref="x1", yref="y1",
x0=-0.5, y0=mean, x1=len(p), y1=mean,
line_width=3, line_color="red")])
fig.update_layout(
showlegend=False,
annotations=[
dict(
x=10,
y=mean,
xref="x",
yref="y",
text="Average price in Madrid",
showarrow=True,
arrowhead=7,
ax=0,
ay=-40
)
]
)
fig.show()
pio.write_image(fig,"images/rent_prices_districts.png")
Average size of houses/flats by districts + average size in Madrid (red line)
p = df.groupby('District')['sq_mt_built'].mean().sort_values(ascending=False).reset_index()
mean = df.sq_mt_built.mean()
fig = px.bar(p, x='District', y='sq_mt_built')
fig.update_layout(
autosize=False,
width=1300,
height=700,
title={
'text': "Average size of houses/flats by districts",
'y':0.9,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'})
fig.update_layout(
shapes=[
dict(type="line", xref="x1", yref="y1",
x0=-0.5, y0=mean, x1=len(p), y1=mean,
line_width=3, line_color="red")])
fig.update_layout(
showlegend=False,
annotations=[
dict(
x=10,
y=mean,
xref="x",
yref="y",
text="Average size in Madrid",
showarrow=True,
arrowhead=7,
ax=0,
ay=-40
)
]
)
fig.show()
pio.write_image(fig,"images/square_meters_districts.png")
Mean rent price by Neighborhoods + Mean rent price in Madrid (red line)
p = df.groupby('Neighborhood')['Avg_price_neigh'].mean().sort_values(ascending=False).reset_index()
mean = df.rent_price.mean()
fig = px.bar(p, x='Neighborhood', y='Avg_price_neigh')
fig.update_layout(
autosize=False,
width=1400,
height=700,
title={
'text': "Average prices for rent by Neghborhoods",
'y':0.9,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'})
fig.update_layout(
shapes=[
dict(type="line", xref="x1", yref="y1",
x0=-0.5, y0=mean, x1=len(p), y1=mean,
line_width=3, line_color="red")])
fig.update_layout(
showlegend=False,
annotations=[
dict(
x=60,
y=mean,
xref="x",
yref="y",
text="Avearge price in Madrid",
showarrow=True,
arrowhead=7,
ax=0,
ay=-40
)
]
)
fig.show()
pio.write_image(fig,"images/rent_prices_neighborhoods.png")
Size by neighborhoods + average square in Madrid (red line)
p = df.groupby('Neighborhood')['sq_mt_built'].mean().sort_values(ascending=False).reset_index()
mean = df.sq_mt_built.mean()
fig = px.bar(p, x='Neighborhood', y='sq_mt_built')
fig.update_layout(
autosize=False,
width=1400,
height=700,
title={
'text': "Size of houses/flats by Neighborhoods",
'y':0.9,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'})
fig.update_layout(
shapes=[
dict(type="line", xref="x1", yref="y1",
x0=-0.5, y0=mean, x1=len(p), y1=mean,
line_width=3, line_color="red")])
fig.update_layout(
showlegend=False,
annotations=[
dict(
x=50,
y=mean,
xref="x",
yref="y",
text="Average size in Madrid",
showarrow=True,
arrowhead=7,
ax=0,
ay=-40
)
]
)
fig.show()
pio.write_image(fig,"images/size_neighborhoods.png"
Box plot of rent price by districts
fig = px.box(df, x="District", y="rent_price").update_xaxes(categoryorder="total descending")
fig.update_layout(
autosize=False,
width=1400,
height=700)
fig.show()
pio.write_image(fig,"images/box_plot_districts.png")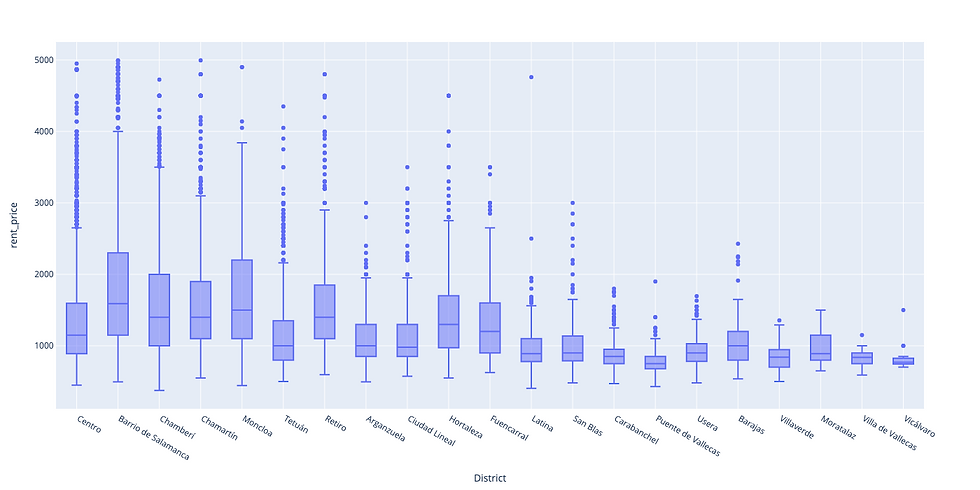
Box plot of rent price by neighborhoods

Box plot for square_mt_built in each district
fig = px.box(df, x="District", y="sq_mt_built").update_xaxes(categoryorder="total descending")
fig.update_layout(
autosize=False,
width=1400,
height=700)
fig.show()
pio.write_image(fig,"images/box_plot_square_districts.png")
Box plot for square_mt_built in each neighborhood
fig = px.box(df, x="Neighborhood", y="sq_mt_built").update_xaxes(categoryorder="total descending")
fig.update_layout(
autosize=False,
width=1800,
height=700)
fig.show()
pio.write_image(fig,"images/box_plot_square_neighborhoods.png")
Scatter plot to check correlation between rent_price and sq_mt_built
fig = px.scatter(df, x="rent_price", y="sq_mt_built")
fig.update_layout(
autosize=False,
width=1200,
height=700)
fig.show()
pio.write_image(fig,"images/scatter_rent_price_sq_mt.png")
This is the end of an EDA part. The main goal of this part was to better understand the given data.
Conclusions:
The majority of rental prices is between 750-2500 euro;
There are 21 districts and 125 neighborhoods in the dataset;
The majority of listings is in Centro, Barrio Salamanca, and Chamberi districts;
Average size of an apartment in the dataset is 88m2;
Average rental price of an apartment in the dataset is 1480 euro;
Boxplots help understand quartiles of rental price and size of houses. Based on this I will further create "clusters";
We can see direct correlation between sq_meter_built and rental price.
Read the second part
Comments