This is the second part of a full pipeline [Exploratory data analysis, data cleaning and preprocessing, modeling, error analysis]. The first part is here.
Full project with data is available on my github.
As mentioned in the first part, there are a lot of NAs in the dataframe and I start with NA treatment.

Quick observations show that the 2 columns 'n_floors' and 'floor' consist of the same information. I will use fillna function to impute NA in 'floor' and drop 'n_floors'.
df.floor.fillna(df.n_floors, inplace=True)
df = df.drop(axis =1, columns = ['n_floors'])I will just drop NAs from 'floor', 'house_type_id' at this stage .
df = df.dropna(axis =0, subset=['floor', 'house_type_id'])There are strings and integers in 'floor'.
df.floor.unique()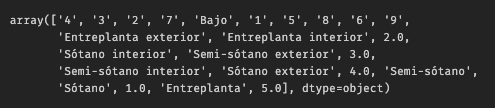
I think it's a drop-down list from the listing website.
So, I will create a function that will recode this to 0 and 0.5.
def text_num(i):
library = {'Bajo':0,'Entreplanta exterior': 0.5,
'Entreplanta interior':0.5, 'Semi-sótano
exterior':0.5, 'Sótano exterior':0.5, 'Sótano
interior':0.5, 'Semi-sótano interior':0.5,
'Sótano':0.5, 'Entreplanta':0.5,
'1':1,'2':2,'3':3,'4':4,'5':5,'6':6, '7':7,
'8':8,'9':9,'10':10,'1.0':1,'2.0':2,'3.0':3,
'4.0':4, '5.0':5, '6.0':6, '7.0':7,
'8.0':8,'9.0':9,'10.0':10}
temp = None
if i in library:
temp = library[i]
return tempApply function to 'floor'
df['floor'] = df['floor'].astype(str).apply(text_num)There are still some nan values, so I will drop them.
df = df[df['floor'].notna()]There are NA values in the columns below, but in fact NA means False here, so I will replace them with False.
varsNaN_False = ['has_central_heating', 'has_individual_heating', 'has_ac', 'has_fitted_wardrobes',
'has_garden', 'has_pool','has_lift', 'has_terrace', 'has_balcony', 'has_storage_room', 'is_accessible',
'has_green_zones', 'is_exterior', 'is_orientation_south']
#Function imputes NA with False
for i in varsNaN_False:
df[i].fillna(False, inplace=True)There are some NAs in 'is_new_development'. I will try to impute them using another column 'built_year'. Obviously, if 'built_year' is earlier than 2019, then it's not a new development.
cond = df[(df['is_new_development'].isnull()) & (df['built_year']<2019)].index
for i in cond:
df.loc[i,['is_new_development']] = FalseAfter all these manipulations our dataframe looks like this

I will delete the columns that I don't need anymore and drop NAs in the rest of them.
df = df.drop(axis =1, columns = ['built_year', 'l30_area_id', 'l40_area_id'])
df = df.dropna(axis =0, subset=['is_new_development', 'is_furnished', 'is_kitchen_equipped' ])My idea is to create a new column based on the sum of several columns. For example, if a house has an elevator, swimming pool, terrace, then it gets 3 points, etc. I hope this feature becomes a good predictor.
columns = df[['is_renewal_needed','has_central_heating',
'has_individual_heating', 'has_ac',
'has_fitted_wardrobes', 'has_lift', 'has_garden',
'has_pool', 'has_terrace',
'has_balcony','has_storage_room','is_accessible',
'has_green_zones']]
df['has_sum'] = columns.sum(axis =1)And change all boolean values to 0 and 1.
columns = ['is_renewal_needed','has_central_heating',
'has_individual_heating', 'has_ac',
'has_fitted_wardrobes', 'has_lift', 'has_garden',
'has_pool', 'has_terrace', 'has_balcony',
'has_storage_room', 'is_accessible','has_green_zones',
'is_floor_under', 'is_new_development', 'sq_mt_built',
'n_bathrooms', 'floor','Avg_price_neigh',
'is_exterior', 'is_orientation_south', 'is_furnished',
'is_kitchen_equipped']
for col in columns:
df[col] = df[col].astype(int)As we know from the EDA part, there are 125 neighborhoods and rental price varies from one neighborhood to another. So I'm going to group these neighborhoods based on the average rental price.
pd.set_option('display.max_rows', 125)
df['rent_price_area'] = df.rent_price/df.sq_mt_built
df.groupby('Neighborhood')['rent_price_area'].mean().sort_values(ascending=False).reset_index()
After plotting the Average mean price by neighborhoods I created 9 groups. The higher the number, the richer the neighborhood.
It's a hard coding without any flexibility. I'm going to change this part later.
#more than 20 euro/m2
group8 = {' Recoletos ', ' Castellana ',' Chueca-Justicia ', ' Almagro '}
#18-20 euro/m2
group7 = {' Lista ', ' Goya ',' Huertas-Cortes ',' Trafalgar ',' Malasaña-Universidad ',' Jerónimos ',' Ciudad Jardín ',' Ibiza ', ' Arapiles ', ' El Viso '}
#16-18 euro/m2
group6 = {' Nueva España ', ' Nuevos Ministerios-Ríos Rosas ', ' Vallehermoso ', ' Lavapiés-Embajadores ', ' Palacio ', ' Gaztambide ', ' Argüelles ', ' Sol ', ' Palos de Moguer ', ' Cuatro Caminos ', ' Cuzco-Castillejos ', ' Bernabéu-Hispanoamérica ', ' Guindalera ', ' Niño Jesús '}
#15-16 euro/m2
group5 = {' Fuente del Berro ',' Bellas Vistas ', ' Prosperidad ', ' Delicias ',' Adelfas ', ' Palomas ', ' Berruguete ', ' Ventilla-Almenara ',' Pacífico ', ' San Pascual ',' Chopera ', ' Amposta ', ' Imperial ', ' Acacias ',' Puerta del Ángel ', ' Conde Orgaz-Piovera ', ' Valdeacederas ', ' Castilla ', ' Hellín ', ' Ciudad Universitaria '}
#14-15 euro/m2
group4 = {' Opañel ', ' Concepción ', ' Fuentelarreina ', ' Aravaca ', ' Estrella ', ' Pilar ', ' Aeropuerto ', ' Numancia ', ' San Juan Bautista ', ' Comillas ', ' Valdezarza ', ' Quintana ', ' Legazpi ', ' Colina ', ' Valdemarín ', ' Casa de Campo '}
#13,5-14 euro/m2
group3 = {' Almendrales ', ' Pueblo Nuevo ', ' Ventas ', ' San Isidro ', ' Costillares ', ' Zofío ',' San Diego ', ' Atalaya '}
#12,5-13,5 euro/m2
group2 = {' La Paz ', ' Lucero ', ' Mirasierra ', ' Los Cármenes ', ' Moscardó ', ' Vista Alegre ', ' Timón ', ' Palomeras Bajas ', ' Valdebebas - Valdefuentes ', ' Salvador ', ' Marroquina ', ' Campamento ', ' Canillas ', ' Rejas ', ' Media Legua ', ' Puerta Bonita ', ' Los Ángeles ', ' Casco Histórico de Barajas ', ' Simancas ', ' Tres Olivos - Valverde ', ' Arcos ', ' Pradolongo ', ' Peñagrande ', ' Pinar del Rey '}
#11,5-12,5 euro/m2
group1 = {' Pavones ', ' Casco Histórico de Vicálvaro ', ' Alameda de Osuna ', ' Los Rosales ', ' Vinateros ', ' Horcajo ', ' 12 de Octubre-Orcasur ', ' Fontarrón ', ' Apóstol Santiago ', ' San Cristóbal ', ' Aluche ', ' Abrantes ', ' Portazgo ', ' Ambroz ', ' El Plantío ', ' Canillejas '}
# 9-11euro m2
group0 = {' Orcasitas ', ' Butarque ', ' Rosas ', ' Santa Eugenia ', ' Casco Histórico de Vallecas ', ' Águilas ', ' San Fermín ',
' Buena Vista ', ' Cuatro Vientos ', ' San Andrés ', ' El Pardo ' , ' Entrevías '}
def cluster_neigh(Neighborhood):
if Neighborhood in group8:
return 8
elif Neighborhood in group7:
return 7
elif Neighborhood in group6:
return 6
elif Neighborhood in group5:
return 5
elif Neighborhood in group4:
return 4
elif Neighborhood in group3:
return 3
elif Neighborhood in group2:
return 2
elif Neighborhood in group1:
return 1
elif Neighborhood in group0:
return 0I'm ready to apply the function and create a new column.
df['Neigh_cluster'] = df.Neighborhood.apply(cluster_neigh)Convert categorical variables into numerical.
df = pd.get_dummies(data=df, columns=['house_type_id','energy_certificate'])This is optional, but I prefer tp have the target value it the end of the dataframe.
temp = df.pop('rent_price')
df['rent_price']=tempI finished data cleaning and preprocessing part and I also did some feature engineering (created new columns). I am almost ready for modeling. One last thing - I would like to check correlation between all features and the target value.
df.corr()['rent_price'][:].sort_values(ascending=False)
I'm going to delete everything below "house_type_id_HouseType 2: Casa o chalet", because these columns have very small correlation to rent price and won't help predict it.
df = df.drop(axis =1, columns = ['has_garden', 'house_type_id_HouseType 5: Áticos', 'is_orientation_south',
'has_pool', 'is_accessible', 'energy_certificate_C', 'energy_certificate_en trámite', 'has_green_zones', 'is_new_development', 'energy_certificate_D', 'house_type_id_HouseType 4: Dúplex','energy_certificate_inmueble exento', 'energy_certificate_B', 'is_renewal_needed',
'is_kitchen_equipped', 'energy_certificate_A', 'energy_certificate_E', 'energy_certificate_no indicado',
'energy_certificate_F', 'energy_certificate_G', 'house_type_id_HouseType 1: Pisos', 'has_individual_heating',
'is_floor_under', 'is_furnished','has_lift'])Save clean data
df.to_csv('df_pre_processed.csv', index =False)End of Cleaning /Preprocessing. The main aim of this part was to prepare the data for modeling.
Conclusions:
This is the most important part. Garbage in - garbage out.
Part of data is lost in this process;
Deleting columns and rows containing NAs is not the best practice, it is always better to try to impute them;
Convert categorical data into numerical. Machine learning uses only numeric values;
Not all columns are good predictors, sometimes less is more;
Functions are faster than loops, especially when working with big dataset.
Read the third part
Comments